21번) 다차원척도법에 대한 설명으로 가장 적절하지 않은 것은?
답 : 개체들 사이의 유사성과 비유사성을 측정하여 차원을 축소하기 위해 사용된다.
해설
■ 3. 데이터 분석
● 다차원 척도법
● 다차원 척도법(Multi Dimensional Scaling, MDS)은 군집분석과 같이 개체들을 대상으로 변수들을 측정한 후, 개체들 사이의 유사성/비유사성을 측정하여 개체들을 2차원 또는 3차원 공간상에 점으로 표현하는 분석 방법입니다.
● 군집분석은 개체들 간의 비유사성을 이용하여 동일한 그룹들로 분류하는 것이 목적인 반면, 다차원척도법은 개체들의 비유사성을 이용하여 2차원 공간상에 점으로 표시하고 개체들 사이의 집단화를 시각적으로 표현하는 것을 목적으로 합니다.
● 주성분분석(Principal Component Analysis, PCA)은 상관관계가 있는 변수들의 선형결합을 통해 변수를 축약하는 기법입니다. 넓은 의미에서는 요인분석(Factor Analysis)의 한 종류로 활용되기도 합니다.
■ 다차원척도법(Multi Dimensional Scaling)
● 객체간 근접성(Proximity)을 시각화하는 통계기법입니다.
● 군집분석과 같이 개체들을 대상으로 변수들을 측정한 후에 개체들 사이의 유사성/비유사성을 측정하여 개체들을 2차원 공간상에 점으로 표현하는 분석방법입니다.
● 개체들을 2차원 또는 3차원 공간상에 점으로 표현하여 개체들 사이의 집단화를 시각적으로 표현하는 분석방법입니다.
■ 다차원척도법 목적
● 데이터 속에 잠재해 있는 패턴(Pattern), 구조를 찾아냅니다.
● 그 구조를 소수 차원의 공간에 기하학적으로 표현합니다.
● 데이터 축소(Data Reduction)의 목적으로 다차원척도법을 이용합니다. 즉, 데이터에 포함되는 정보를 끄집어내기 위해서 다차원척도법을 탐색수단으로써 사용합니다.
● 다차원척도법에 의해서 얻은 결과를, 데이터가 만들어진 현상이나 과정에 고유의 구조로서 의미를 부여합니다.
■ 다차원척도법 방법
● 개체들의 거리 계산에는 유클리드 거리행렬을 활용합니다.

● 관측대상들의 상대적 거리의 정확도를 높이기 위해 적합 정도를 스트레스 값(Stress Value)으로 나타냅니다.
● 각 개체들을 공간상에 표현하기 위한 방법은 부적합도 기준으로 Stress나 S-Stress를 사용합니다.
● 최적모형의 적합은 부적합도를 최소로 하는 반복 알고리즘을 이용하며, 이 값이 일정 수준 이하가 될 때 최종적으로 적합된 모형으로 제시합니다.
● 스트레스 값은

● Stress와 적합도 수준 M은 개체들을 공간상에 표현하기 위한 방법으로 Stress나 S-Stress를 부적합도 기준으로 사용합니다.
● 최적모형의 적합은 부적합도를 최소로 하는 방법으로 일정 수준 이하로 될 때까지 반복해서 수행합니다.
| Stress | 적합도 수준 |
| 0 | 완벽(Perfect) |
| 0.05 이내 | 매우 좋은(Excellent) |
| 0.05 ~ 0.10 | 만족(Satisfactory) |
| 0.10 ~ 0.15 | 보통(Acceptable, but Doubt) |
| 0.15 이상 | 나쁨(Poor) |
■ 다차원척도법 종류
◆ 계량적 MDS(Metric MDS)
● 데이터가 구간척도나 비율척도인 경우 활용합니다.(전통적인 다차원척도법) N개의 케이스에 대해서 p개의 특성변수가 있는 경우, 각 개체들간의 유클리드 거리행렬을 계산하고 개체들간의 비유사성 S(거리제곱 행렬의 선형함수)를 공간상에 표현한다.


◆ 비계량적 MDS(nonmetric MDS)
● 데이터가 순서척도인 경우 활용한다. 개체들 간의 거리가 순서로 주어진 경우에는 순서척도를 거리의 속성과 같도록 변환(Monotone Transformation)하여 거리를 생성한 후 적용한다.

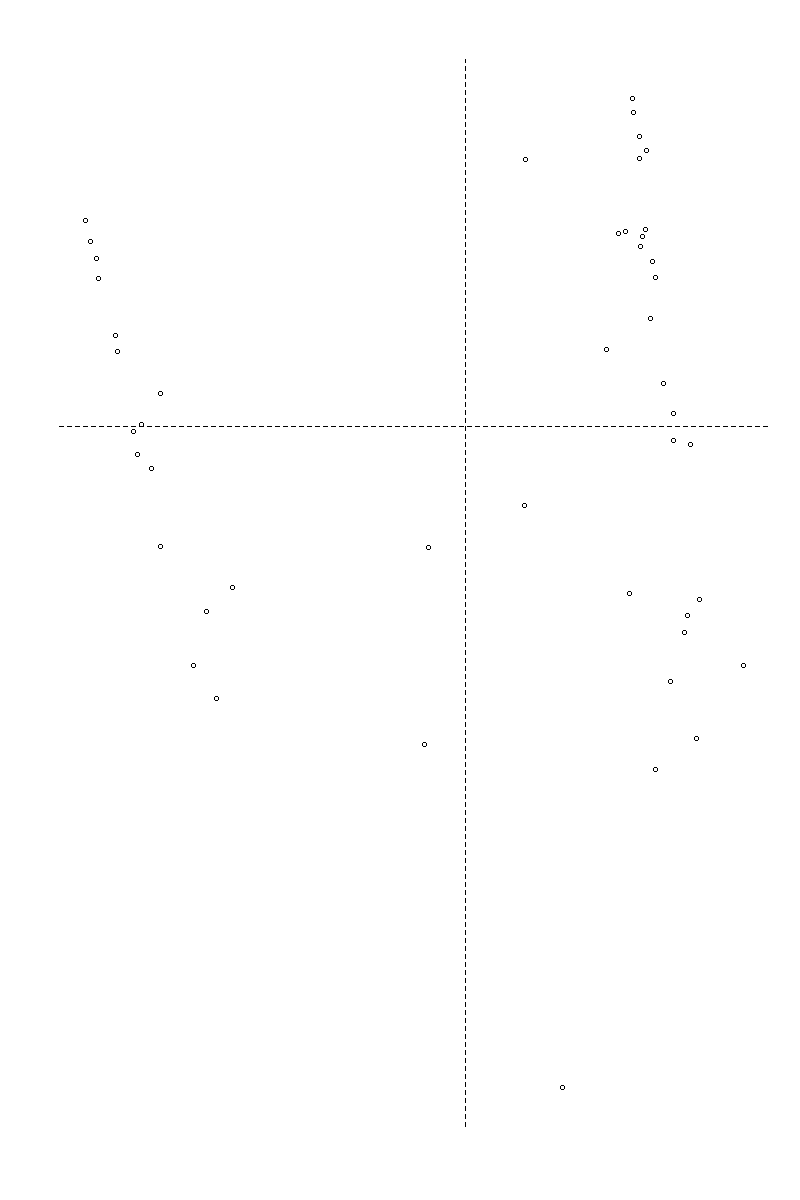


22번) 이상치 판정 방법 중 가장 부적절한 것은?
답 : Q2(중위수) + 1.5*IQR 보다 크거나 Q2(중위수) - 1.5*IQR 작은 데이터를 이상치로 규정
해설
■ 이상값(Outlier) 인식과 처리
◆ 이상값이란?
● 의도하지 않게 잘못 입력한 경우(Bad Data)
● 의도하지 않게 입력되었으나 분석 목적에 부합되지 않아 제거해야 하는 경우(Bad Data)
● 의도하지 않은 현상이지만 분석에 포함해야 하는 경우
● 의도된 이상값(Fraud, 불량)인 경우
● 이상값을 꼭 제거해야 하는 것은 아니기 때문에 분석의 목적이나 종류에 따라 적절한 판단이 필요하다.
◎ 이상치 사용 분야
- 사기 탐지, 의료(특정환자에게 보이는 예외적인 증세), 네트워크 침입탐지 등
◆ 이상값의 인식 방법
◆ ESD(Extreme Studentized Deviation)
● 평균으로부터 3 표준편차 떨어진 값(각 0.15%)

◆ 기하평균 - 2.5 * 표준편차 < data < 기하평균 + 2.5 * 표준편차
◆ 사분위수 이용하여 제거하기(상자 그림의 outer fence 밖에 있는 값 제거)
이상값 정의 : Q1 * 1.5(Q3 - Q1) < data < Q3 + 1.5(Q3 - Q1)를 벗어나는 데이터
23번) 표본추출의 방법으로 틀린 것은?
답 : 집단추출법
해설
◆ 표본 추출 방법
● 표본조사의 중요한 점은 모집단을 대표할 수 있는 표본 추출이므로 표본 추출 방법에 따라 분석결과의 해석은 큰 차이가 발생한다. (N개의 모집단에서 n개의 표본을 추출하는 경우)
◆ 단순랜덤 추출법 (Simple Random Sampling)
● 각 샘플에 번호를 부여하여 임의의 n개를 추출하는 방법으로 각 샘플은 선택될 확률이 동일하다. (비복원, 복원(추출한 Element를 다시 집어 넣어 추출하는 경우) 추출)
◆ 계통추출법 (Systematic Sampling)
● 단순랜덤추출법의 변형된 방식으로 번호를 부여한 샘플을 나열하여 K개씩 (K = N / n) n개의 구간으로 나누고 첫 구간(1, 2, ..., K)에서 하나를 임의로 선택한 후에 K개씩 띄어서 n개의 표본을 선택한다. 즉, 임의의 위치에서 매 k번째 항목을 추출하는 방법이다.
◆ 집락추출법 (Cluster Random Sampling)
● 군집을 구분하고 군집별로 단순랜덤 추출법을 수행한 후, 모든 자료를 활용하거나 샘플링하는 방법이다. (지역표본추출, 다단계표본추출)
◆ 층화추출법 (Stratified Random Sampling)
● 이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법으로, 유사한 원소끼리 몇 개의 층 (Stratum)으로 나누어 각 층에서 랜덤 추출하는 방법이다. (비례층화추출법, 불비례층화추출법)
24번) R의 데이터 구조에서 숫자형, 문자형, 논리형을 모두 합쳐 하나의 벡터를 구성하였을 경우 합쳐진 벡터의 형식은?
답 : 문자형 벡터
해설
◆ 문자형 벡터는 문자열로 된 집합이다.
25번) 신경망 모형에서 출력값이 여러 개이고 목표치가 다범주인 경우에 사용하는 활성 함수는?
답 : 소프트맥스
해설
◆ 소프트맥스(Softmax) 함수
- 표준화지수 함수로도 불리며, 출력값이 여러 개로 주어지고 목표치가 다범주인 경우 각 범주에 속할 사후확률을 제공하는 함수이다.

26번) 표본들이 서로 관련된 경우 짝지어진 두 관찰치의 크고 작음을 표시하여 그 두 분포의 차이에 대한 가설을 검증하는 방법은?
답 : 부호 검정(sign test)
해설
◆ 부호 검정
- 부호검정은 위치모수에 대한 비모수적 검정 중에서 가장 오래된 검정 중의 하나로, Fisher에 의해 1925년부터 사용되었으며, 간단하고 사용하기 쉬워 현재까지도 상당히 유용하게 쓰이고 있다.
이 방법은 단지 위치모수 Θ0보다 큰 관측값(Xi ... Xn)들의 개수만을 이용하여 관측값 Xi와 위치모수 Θ0의 차이인 (Xi - Θ0)에 대해 단지 부호만을 검정에 이용한다.
27번) 인공신경망 모형에서 활성 함수인 시그모이드(sigmoid) 함수의 결과값은?
답 : 0 ≤ y ≤ 1
해설
28번) 분류 모형의 평가를 위해 사용되는 방법으로 틀린 것은?
답 : 덴드로그램
해설
29번) 자료의 측정수준에 대한 설명으로 부적절한 것은?
답 : 비율척도는 ... 사칙연산이 가능하고 ... 혈액형, 학력 등이 해당된다.
해설
30번) 군집분석에 대한 설명으로 적절하지 않은 것은?
답 : 군집분석은 집단 간 이질성과 집단 내 동질성이 모두 낮아지는 방향으로 군집을 만든다.
해설
31번) 빅데이터 분석 프로세스에서 모델링 단계에 해당하지 않는 과정은?
답 : 수행방안 설계
해설
32번) 코드 실행 결과에 대한 설명으로 적절한 것은?
답 : 회귀모형은 유의수준 5% 하에서 통계적으로 유의미하다.
해설
33번) 아래 수식에 해당하는 데이터 간의 거리 계산 방식은?
답 : 맨하튼 거리
해설
34번) 군집분석 기법으로 적절하지 않은 것은?
답 : Silhouette Coefficient
해설
35번) 의사결정나무의 특징으로 틀린 것은?
답 : 비정상적인 잡음 데이터에 대해서는 민감하게 분류한다.
해설
36번) 연관분석에 대한 특징으로 틀린 것은?
답 : 분석을 위한 계산이 복잡하다는 단점이 있다.
해설
37번) 데이터 분할에 대한 설명으로 적절하지 않은 것은?
답 : 검정용 데이터는 학습 과정에서 사용되지 않는다.
해설
38번) 변수 가공에 대한 설명으로 적절하지 않은 것은?
답 : 구간화의 개수가 감소하면 정확도는 높아지지만 속도가 느려진다.
해설
39번) 모형평가 방법으로 적절하지 않은 것은?
답 : 엔트로피
해설
40번) 데이터 전처리 과정에 대한 설명으로 맞는 것은?
답 : 데이터 특성을 파악하고 통찰을 얻기 위한 방법을 데이터 EDA라고 한다.
해설
'ADsP 자격증 공부' 카테고리의 다른 글
| ADsP 36회 기출문제 객관식 10문 (0) | 2024.07.06 |
|---|---|
| ADsP 36회 기출문제 객관식 10문제 (1) | 2024.07.05 |

